Everything your team needs to deploy, monitor, and scale ML models in production.
Connect your model artifact from any source — MLflow, S3, or a Docker image. MLPipeX builds the container, provisions the compute, and exposes a production-grade REST endpoint. No Kubernetes expertise required.
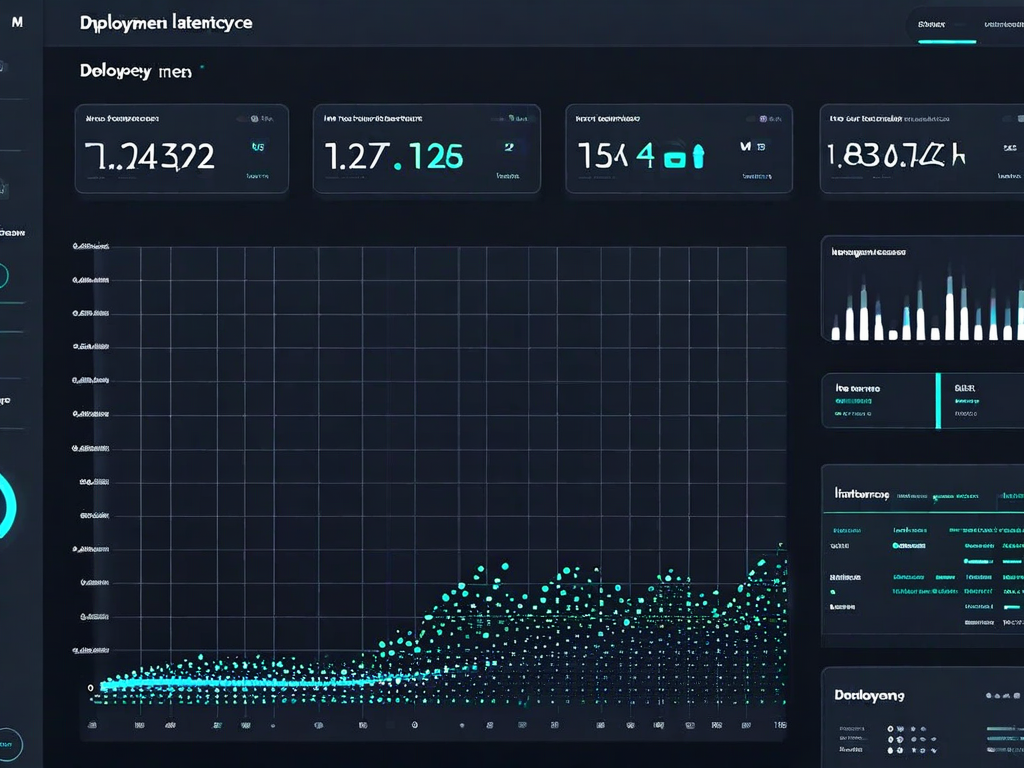
Track latency percentiles, prediction distributions, feature drift, and data quality in real time. Set alert thresholds and get notified before your model starts hurting users.
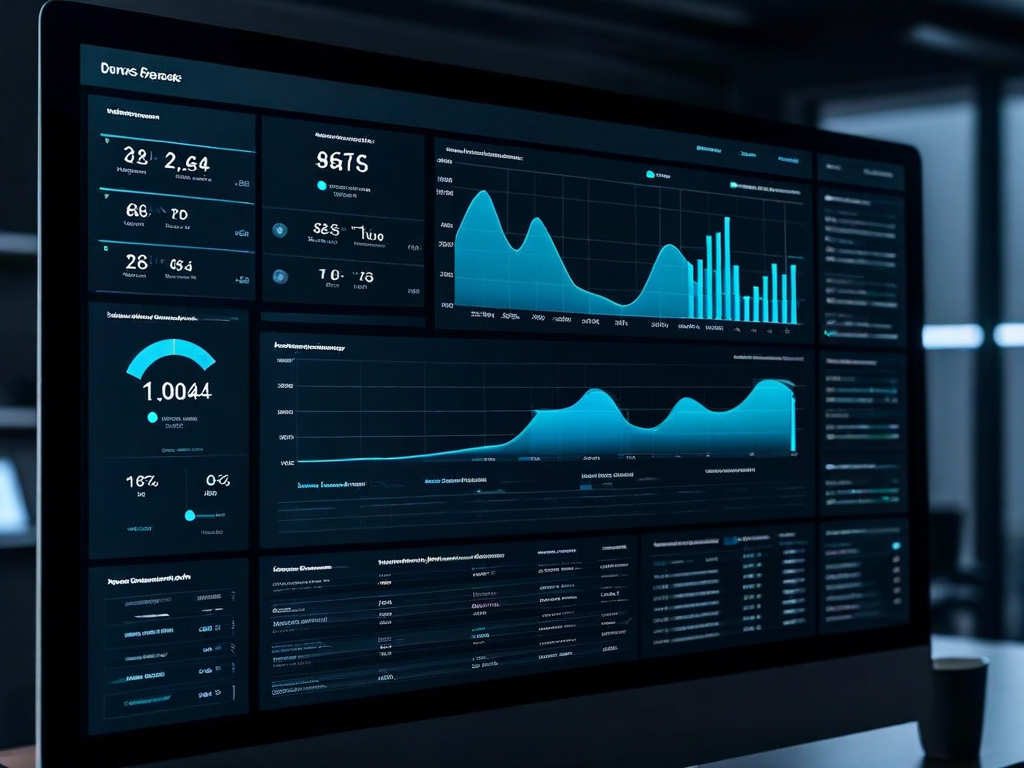
Define triggers — schedule, drift threshold, or data volume — and MLPipeX handles the rest. Kick off training jobs, run validation gates, and promote to production automatically.
Built on open standards. Designed for enterprise scale.
Connect to any data store. Built-in feature store with point-in-time correctness.
CPU and GPU inference support. Automatic batching and quantization options.
Deploy to EU, US, and APAC regions. Data residency controls for compliance.
RBAC with team-level isolation. SAML SSO and API key management built in.
Python SDK and CLI for every workflow. Full API access with OpenAPI docs.
Sub-10ms P99 latency for small models. Streaming inference for LLM workloads.